쿠버네티스 스케줄링

- 스케줄링이란, 쿠버네티스에서 Pod를 어느 노드에 배포할지를 결정하는 것
스케줄러의 노드 선택
- 1단계, 노드 필터링
- 특정 리소스 요청을 충족시키기 충분한 노드를 filtering
- 2단계, 노드 스코어링(scoring)
- 배치할 수 있는 노드의 순위를 지정하여 종합적으로 고려
- 동일한 점수인 경우 스케줄러가 임의로 선택
- 쿠버네티스가 선택한 노드가 최적의 선택인 확률이 높음
- 스케줄러의 필터링 및 스코어링 동작을 구성하기 위한 방법도 존재함
특정 노드 레이블에 파드 할당

- Node Selector
- 파드가 배치될 노드를 특정 레이블을 명시하여 결정
- 가장 간단하고 유연한 방법

- Taint and Tolerations
- 파드가 배치될 수 없는 노드를 지정
- 옵션
- NoSchedule : 파드가 스케줄되지 않음
- PreferNoSchedule : 되도록 파드를 배치하지 않음
- NoExecute : 이미 있는 파드도 모두 제거함
- NodeAffinity
- 노드 어피니티는 nodeSelector 필드와 비슷하지만 조금 더 구체적으로 지정하는 기능
- 노드의 레이블을 기준으로 새로운 파드가 특정 워커 노드로 배포되도록 스케줄링
- 조건 :
- soft 규칙 (preferredDuringSchedulingIgnoredDuringExecution)
- 파드를 조건에 따라 노드에 배포하려고 시도는 하지만 보증할 수 없다는 의미
- hard 규칙 (requiredDuringSchedulingIgnoredDuringExecution)
- 파드가 노드에 스케줄 되도록 반드시 규칙에 만족해야 한다는 의미
- nodeSelector랑 비슷하며, NodeAffinity는 복잡하기 때문에 보통 nodeSelector를 사용함
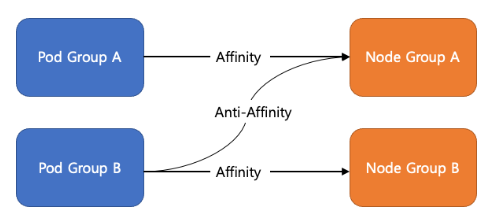
- podAffinity / podAntiAffinity
- 새로운 파드가 기존에 실행 중인 파드를 고려하여 노드를 선택하는 스케줄링
- podAffinity :동일한 파드가 같은 워커 노드에서 실행되도록 지정
- podAntiAffinity : 동일한 파드가 다른 워커 노드에서 실행되도록 지정
- 조건 :
- soft 규칙 (preferredDuringSchedulingIgnoredDuringExecution)
- 파드를 조건에 따라 노드에 배포하려고 시도는 하지만 보증할 수 없다는 의미
- hard 규칙 (requiredDuringSchedulingIgnoredDuringExecution)
- 파드가 노드에 스케줄 되도록 반드시 규칙에 만족해야 한다는 의미
- topologySpreadConstraints(토폴로지 분배 제약 조건)
- 클러스터에 걸쳐 파드가 분배되는 방식을 제어할 수 있다.

자원 할당과 스케일 조정
- 쿠버네티스 입장에서는 애플리케이션의 필요한 자원의 양을 알아야 그 만한 자원이 가용한 노드에 파드를 배포할 수 있다.
리소스 조정
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
- requests : 파드가 노드에 배치될 때 확보되어야 하는 자원
- limits : 파드가 최대한 사용할 수 있는 자원
kind: Deployment
metadata:
name: my-app
spec:
replicas: 5
auto Scaling

- VPA (Vertical Pod Scaling) : 워크로드 자체에 할당된 컴퓨팅 자원을 조정

- HPA (Horizontal Pod Scaling) : 워크로드의 수량을 조정
- 스케일링 과정
- 메트릭이 파드의 사용량 측정하여 컨트롤러에 전달
- 컨트롤러는 스케일링이 필요한 상황을 파악하고 분석
- 컨트롤러는 리소스 사용량에 따라 pod개수를 조정
- 따라서, HPA를 사용하기 위해서 메트릭 서버가 필요함
HPA 설정
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa-cpu
spec:
scaleTargetRef: # replica수를 조정할 대상 설정
apiVersion: apps/v1
kind: Deployment
name: myapp-deploy-hpa
minReplicas: 2 # replica 최소값
maxReplicas: 10 # replica 최대값
targetCPUUtilizationPercentage: 70 # 70퍼센트를 기준으로 스케일링
- 목표로 하는 자원 사용량 및 Pod 수량을 설정
- apiVersion v2에서는 memory, 외부 metrics 등으로 설정할 수 있다.
v1에서는 CPU 사용률만 제공
- HPA 알고리즘
- 원하는 레플리카 수 = ceil(현재 레플리카 수 * (현재 메트릭 값 / 원하는 메트릭 값))
- 워크로드 스케일링 안정성 고려사항
- 잦은 스케일링은 리소스가 많이 소모 되므로 적정 리소스양을 할당하여 특정 임계값이 넘어갈 때 스케일링 되도록 설정해야 함
- 스케일링 기본 세팅 시간
- 스케일 아웃 : 180초
- 스케일 인 : 300초
파드 중단 사례
- 클러스터에서 파드가 중단되는 사례
- 비자발적 중단
- 물리 하드웨어 오류
- VM 삭제 또는 VM 장애
- 노드의 리소스 부족으로 파드 축출
- 자발적 중단
- deployment 제거 또는 컨트롤러 제거
- deployment 업데이트
- 사용자의 파드 삭제
- 노드 복구 및 업그레이드
- 클러스터의 스케일 축소
- 쿠버네티스 분산 처리 시스템 환경에서는 갑작스러운 파드 종료가 발생할 수 있기 때문에 애플리케이션 대응 처리도 필요함
